
Premiers pas dans l’écosystème Amazon Web Services
Salut tout le monde ! Dans cet article, nous allons franchir les premiers pas passionnants dans l’environnement AWS en déployant une application de liste de tâches avec Python.
Notre objectif est de construire une application web permettant aux visiteurs connectés de gérer leur liste de tâches. Pour ce faire, nous utiliserons le modèle d’application sans serveur AWS SAM (Serverless Application Model) afin de déployer les services backend tels que l’API Gateway, les fonctions Lambda pour la logique, une table DynamoDB pour les données et Amazon Cognito pour la gestion des accès.
Le frontend de notre application sera hébergé sur S3 derrière une distribution CloudFront. Notre frontend sera assez basique puisque nous nous concentrerons plutot sur la manière dont les ressources sont créées et déployées sur AWS.
Prêts pour cette première incursion dans l’univers AWS ? Commençons !
Aperçu
Nous allons en revue la configuration générale de l’application et expliquer comment elle est déployée. Cet article sera principalement théorique mais tout le code est disponible dans ce dépôt GitHub.
Pour accèder à l’interface utilisateur de l’application, cliquer ici.
À propos de l’application
Notre application est un gestionnaire de liste de tâches qui aide un utilisateur à les gérer ainsi que tous fichiers ou pièces jointes attachés. L’utilisateur peut également trouver des tâches spécifiques grâce à la fonction de recherche.
Fonctionnalités de base
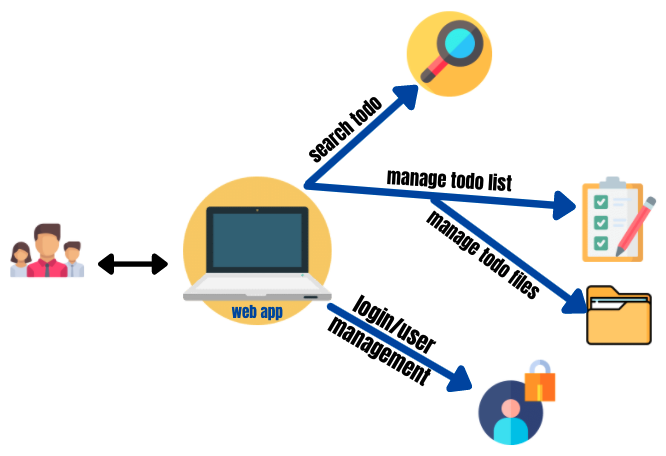
L’image ci-dessus devrait décrire les fonctionnalités de base de l’application.
Gestion des utilisateurs et Authentification
L’utilisateur est appelé a créer un profil puis à se connecter à la plateforme. Une fois ses actions terminées, il peut se déconnecter.
Recherche de tâches
Les utilisateurs peuvent effectuer une recherche de tâches par mot-clé. Les résultats de cette recherche ne portent que sur les tâches créées par l’utilisateur connecté. Notre applciation est en mesure de déterminer les objets appartenant a un utilisateur précis.
Ajout d’une nouvelle tâche
Les utilisateurs peuvent ajouter de nouvelles tâches à enregistrer dans l’application.
Prise en charge des fichiers
Les utilisateurs peuvent téléverser des piéces jointes pour chaque tâche. Ces fichiers sont ensuite servis à l’utilisateur via le réseau de distribution de contenu Amazon CloudFront.
Composants de l’application
Maintenant que nous avons une compréhension de base de l’application, voyons comment toutes ces fonctionnalités se traduisent par différents composants techniques. L’image ci-dessous donne une vue d’ensemble de chaque couche de l’application et des composants techniques impliqués.
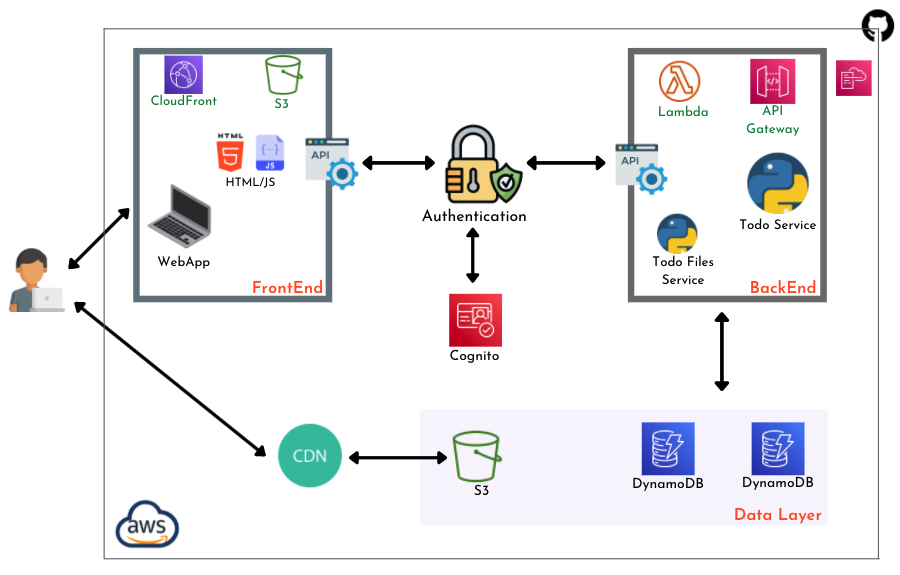
Parcourons chaque composant :
Frontend
Le Frontend de l’application est constitué de fichiers HTML et Javascript. Toutes les opérations et communications avec le backend sont effectuées via divers points d’accès REST API.
Backend
Le Backend est construit avec des fonctions Lambda qui sont déclenchées par des appels REST API. Il offre divers points d’accès pour effectuer des fonctionnalités d’application telles que l’ajout ou la suppression de tâches, l’ajout ou la suppression de fichiers de tâches, etc.
Les point d’accès REST API sont déployés à l’aide de Amazon API Gateway qui nous permet aussi d’intégrer la couche d’authentification. Le CORS est activé pour l’API, de sorte qu’elle n’accepte que les demandes prevenant du frontend.
Couche de données
Une table DynamoDB est utilisée pour stocker toutes les tâches et les données associées. Les fonctions Lambda effectuent toutes les opérations de base de données en recevant des demandes du frontend et en se connectant à la table . DynamoDB est un service sans serveur qui offre une mise à l’échelle automatique ainsi qu’une haute disponibilité.
Authentification
L’authentification est gérée par Amazon Cognito. Nous utilisons un pool d’utilisateurs Cognito pour stocker les métadonnées des utilisateurs. Lorsqu’un utilisateur se connecte et qu’une session est établie avec l’application, le jeton de session et les métadonnées associées sont stockés côté frontend et envoyés via les points d’accès API. API Gateway valide ensuite le jeton de session avec Cognito et permet aux utilisateurs d’effectuer des opérations d’application.
Service de fichiers
Il existe un service distinct pour gérer la gestion des fichiers de l’application. Le service de fichiers est composé d’une fonction JavaScript utilisant le SDK AWS (pour les opérations de téléchargement de fichiers), de fonctions Lambda + API Gateway pour les appels API vers diverses opérations sur les fichiers telles que la récupération des informations sur les fichiers, la suppression de fichiers, etc.
S3 et DynamoDB sont utilisés pour stocker les fichiers et les informations sur les fichiers. Les fichiers sont renvoyés à l’utilisateur via l’application à l’aide du réseau de diffusion de contenu (CDN) CloudFront. Le CDN permet de servir les fichiers statiques globallement, et les utilisateurs peuvent y accéder plus rapidement et plus facilement.
Architecture
À présent que nous disposons d’une compréhension des divers composants et services impliqués, explorons comment organiser et interconnecter ces éléments pour aboutir à la version finale fonctionnelle de l’application.
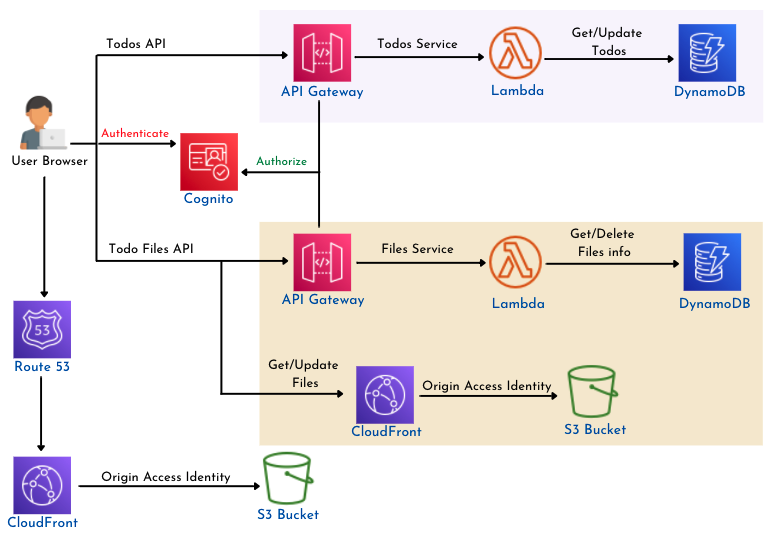
Frontend
Les fichiers HTML, JavaScript et CSS statiques générés pour le site Web seront stockés dans un compartiment S3. Celui-ci est configuré pour héberger un site Web et fournit un point d’accès par lequel l’application peut être consultée.
Pour améliorer les performances côté frontend, le compartiment S3 est sélectionné comme origine pour une distribution CloudFront.
Fonctions Lambda pour la logique des services backend
Toute la logique backend est déployée sous la forme de fonctions AWS Lambda. Les fonctions Lambda sont « sans serveur » et pour les déployer, nous devons téléverser les fichiers de code Python.
Ci-dessous les fonctions qui sont déployées :
Service de Tâches
getTodos: récupérer toutes les tâches pour un userIDgetTodo: retourner les informations détaillées sur une tâche en fonction de l’attribut todoIDaddTodo: créer une tâche pour l’utilisateur connecté en fonction du userIDcompleteTodo: mettre à jour l’enregistrement de la tâche et définir l’attribut completed sur TRUE en fonction de todoIDaddTodoNotes: mettre à jour l’enregistrement de la tâche et définir les notes sur l’attribut à la valeur spécifiée en fonction de todoIDdeleteTodo: supprimer une tâche pour l’utilisateur connecté en fonction de userID et todoID
Service de Fichiers
getTodoFiles: récupérer tous les fichiers appartenant à la tâche spécifiéeaddTodoFiles: ajouter des fichiers en tant que pièces jointes à la tâche spécifiéedeleteTodoFiles: supprimer les fichiers sélectionnés pour la tâche spécifiée
API Gateway pour exposer les fonctions Lambda
API Gateway définit tous les points d’accès REST API pour rediriger les requêtes frontend vers la fonction Lambda appropriée dans le backend. Chaque service du backend dispose de son propre API avec des ressources déployées comme suit :
Service de Tâches
getTodos: /{userID}/todosgetTodo: /{userID}/todos/{todoID}deleteTodo: /{userID}/todos/{todoID}/deleteaddTodo: /{userID}/todos/addcompleteTodo: /{userID}/todos/{todoID}/completeaddTodoNotes: /{userID}/todos/{todoID}/addnotes
Service de Fichiers
getTodoFiles: /{todoID}/filesaddTodoFiles: /{todoID}/files/uploaddeleteTodoFiles: /{todoID}/files/{fileID}/delete
La ressource API addTodoFiles déclenche la fonction addTodoFiles, qui enregistre uniquement les informations sur le fichier telles que le nom du fichier et le chemin/clé du fichier dans une table DynamoDB.
La même table est interrogée par la fonction getTodoFiles pour afficher les informations des fichiers renvoyées. L’opération réelle de téléversement des fichiers vers S3 est effectuée par une fonction JavaScript dans le code frontend.
Ceci nous permet d’éviter qu’une grande quantité de données ne passe par les fonctions Lambda et augmente ainsi le temps de réponse et le coût.
Base de données
Les tables DynamoDB sont utilisées comme bases de données. Nous avons deux tables respectivement pour le service de Tâches et le service de Fichiers.
La fonction de recherche de l’application est gérée par des requêtes de recherche DynamoDB simples. Nous pouvons déployer un cache DynamoDB Accelerator devant les tables pour augmenter les performances si nécessaire.
Service de Tâches
Pour simplifier les choses, chaque document dans DynamoDB représentera une tâche avec les attributs suivants :
todoID: numéro unique identifiant la tâche, servira de clé primaireuserID: ID de l’utilisateur qui a créé la tâche, servira de clé de tridateCreated: date à laquelle la tâche a été créée, date du jourdateDue: date à laquelle la tâche doit être terminée, fournie par l’utilisateurtitle: titre de la tâche, fourni par l’utilisateurdescription: description de la tâche, fournie par l’utilisateurnotes: notes supplémentaires pour la tâche, peuvent être ajoutées à tout moment après la création de la tâche, vides par défautcompleted: vrai ou faux si la tâche est marquée comme terminée
Service de Fichiers
fileID: numéro unique identifiant le fichier, servira de clé primairetodoID: ID de l’élément de tâche auquel il appartient, servira de clé de trifileName: nom du fichier téléchargéfilePath: URL du fichier téléchargé pour les téléchargements
Stockage de fichiers
Pour prendre en charge la fonctionnalité de gestion des fichiers de l’application, un stockage de fichiers doit être déployé. Nous utilisons un compartiment S3. Le service de fichiers appelle l’API AWS S3 pour stocker les fichiers dans le compartiment.
Infrastructure en tant que Code (IaC) et Déploiement de l’application
Les services backend de l’application sont définis dans des fichiers gabarits du SAM (Serverless Application Model) – similaire à des gabarits CloudFormation. Chaque service dispose de son propre gabarit et les ressources sont configurées pour être aussi indépendantes que possible.
Nous utilisons des déploiements automatisés pour l’ensemble de l’environnement de l’application: frontend et deux services backend. Chaque service est déployé à l’aide d’un pipeline de déploiement distinct pour maintenir un découplage optimal. Les composants ci-dessous sont utilisés:
- Un référentiel GitHub pour stocker les fichiers de code
- Une branche distincte pour les changements en environnement de production (la branche principale demeurre pour l’environnement de développement)
- Chaque services (frontend et 2 services backend) dispose de son sous-dossier.
- Tout commit sur un dossier de service dans une branche spécifiée (Prod ou Dev) déclenche une phase de test puis déploiement automatiquement des modifications sur le service dans l’environnement approprié.
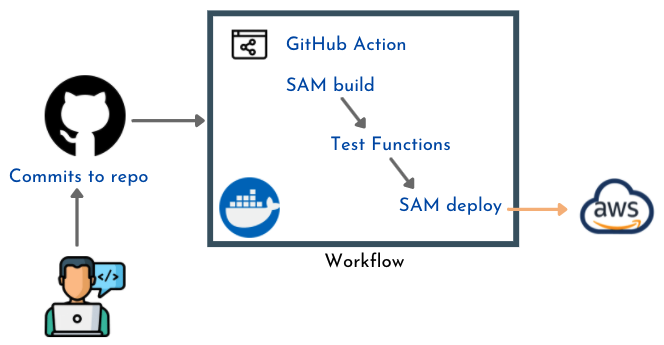
- Nous utilisons des Actions GitHub pour les flux de travail des déploiements.
FrontEnd
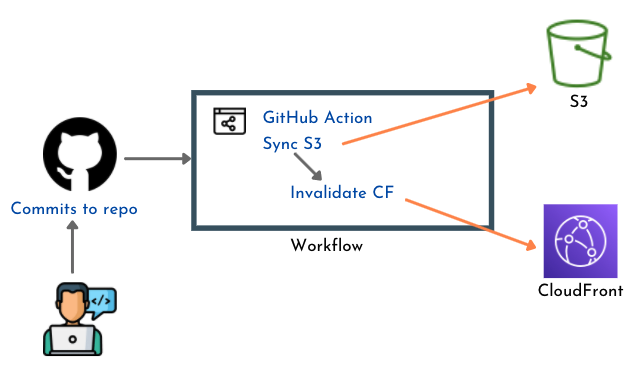
Backend
Pour conclure
Nous avons exploré ensemble l’architecture d’une application « sans serveur » basique utilisant le modèle de microservices sur AWS. Ceci nous permet de découvrir certains services phares de ce fournisseur infonuagique, tel que Lambda, API GAteway, S3, DynamoDB, CloudFront.
L’objectif premier de cette application pilote est de découvrir et d’apprendre. Il y a beaucoup d’améliorations à apporter, mais nous espérons que ce projet initial servira de tremplin pour affiner nos compétences et explorer davantage les possibilités offertes par l’infonuagique AWS.